AI Music Tools News
Hands-on coverage of AI music tools, vetted for musicians.
I cover the latest tool launches and updates, write step-by-step tutorials, rank the best AI music tools by use case, and run head-to-head comparisons. Every recommendation comes from hands-on testing.
- 28 Jul
 Tool News & Updates 28 Jul
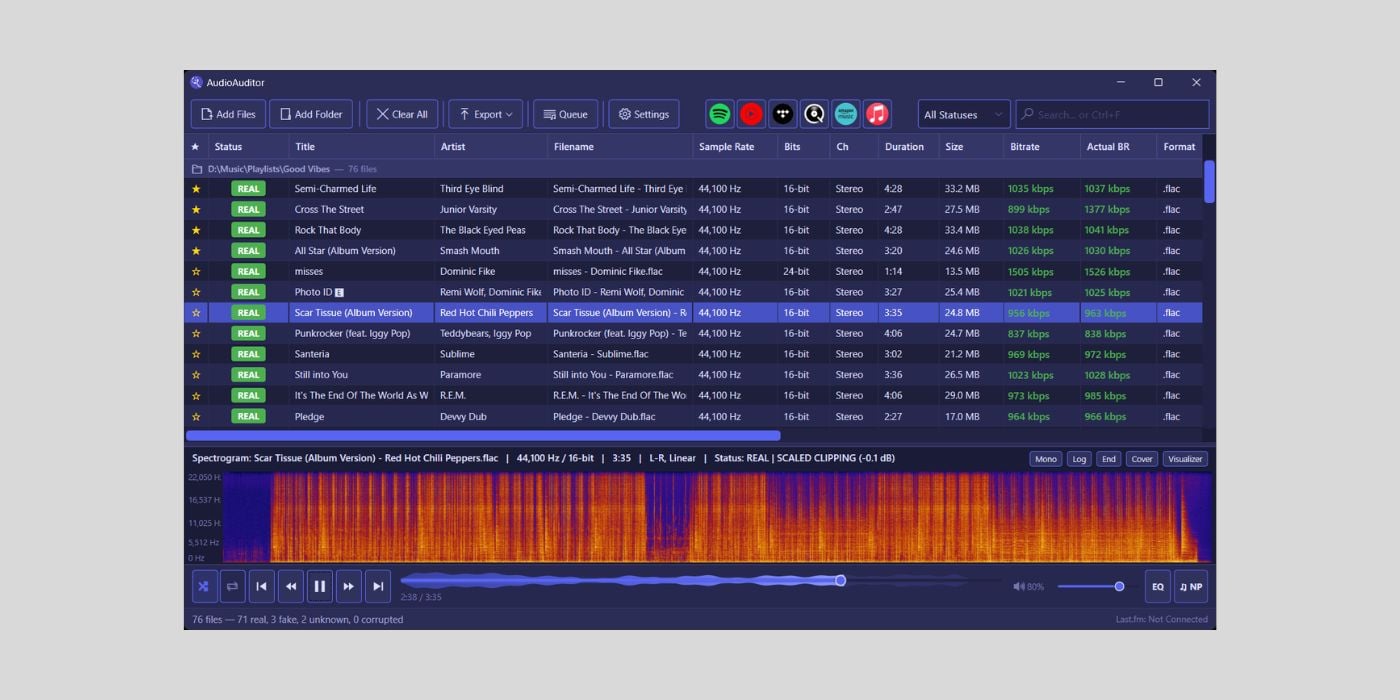
Tool News & Updates 28 JulAudioAuditor bundles AI music detection, spectral analysis and AcoustID fingerprinting for free
- AudioAuditor is a free, open-source audio analyser and player built by developer Angel2mp3 on Microsoft .NET 8.
- Its AI music detection feature is still marked beta.
- The toolkit also covers fake stereo, fake lossless and MQA detection, plus AcoustID fingerprinting.
- 22 Jul
 Tool News & Updates 22 Jul
Tool News & Updates 22 JulSplice cuts staff in "strategic restructuring," refocuses on next-gen AI tools
- Splice confirmed to MusicTech on July 22, 2026 that it is cutting some staff roles in a strategic restructuring.
- The company says it is refocusing investment on building the next generation of AI music tools.
- The cuts follow Splice's May 2026 partnership with ElevenLabs to build AI creative tools using ElevenLabs' music models.
- 17 Jul
 Tool News & Updates 17 Jul
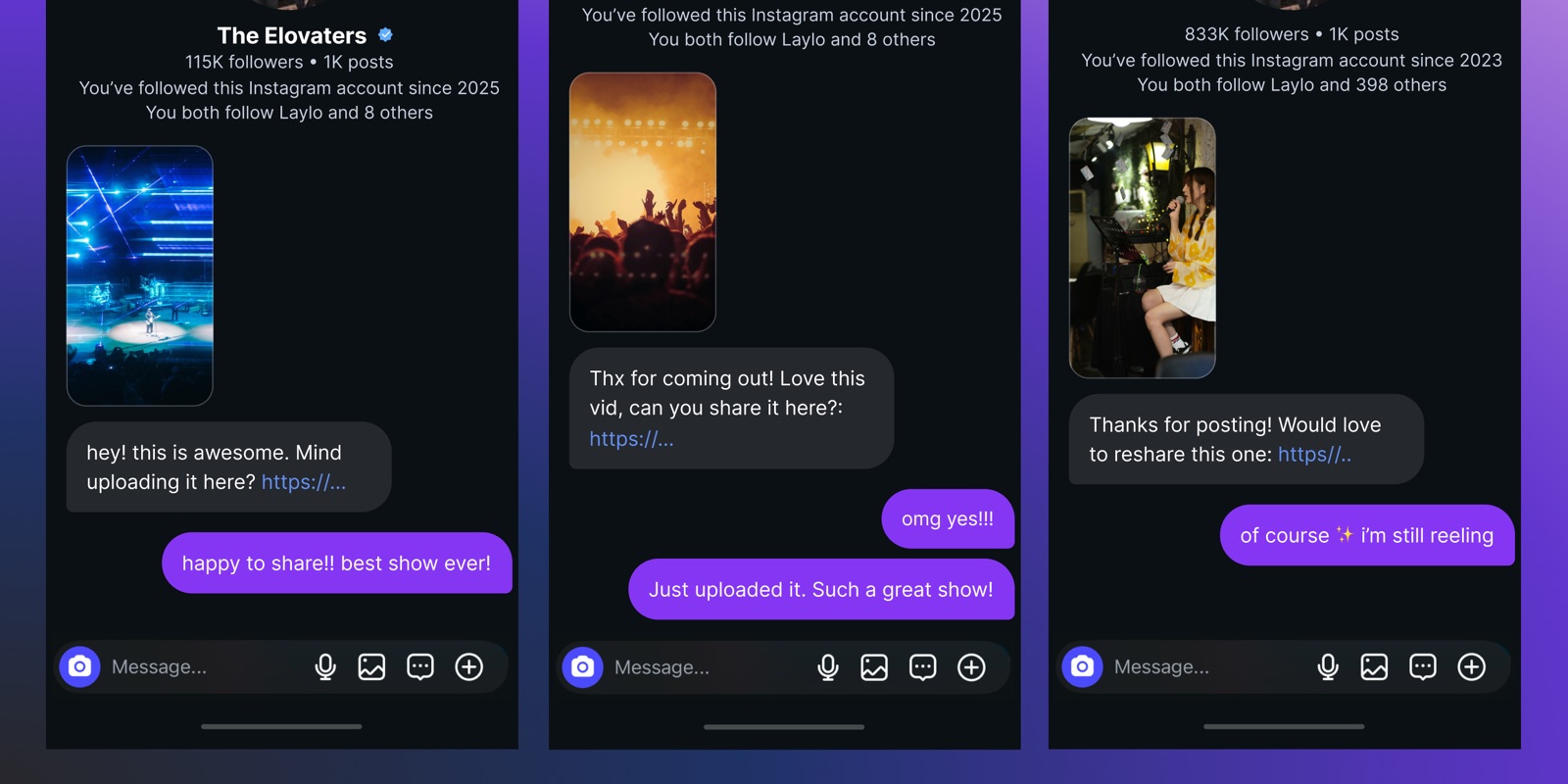
Tool News & Updates 17 JulLaylo's UGC Agent auto-collects fan clips from Instagram Stories
- Laylo launched the UGC Agent on July 14, 2026, an AI agent monitoring an artist's Instagram Story tags for fan clips worth keeping
- The agent DMs the fan for the original file and reuse permission before the Story expires after 24 hours
- One band sent over 250 Instagram DMs in a weekend through the agent and collected hundreds of fan videos with permission
- 17 Jul
 Tool News & Updates 17 Jul
Tool News & Updates 17 JulUdio signs a DRM deal with BuyDRM ahead of its licensed platform launch
- Udio has signed a deal with Austin-based BuyDRM to protect its AI music streams with the KeyOS MultiKey service, announced July 14, 2026
- The agreement gives Udio multi-DRM coverage across Google Widevine, Apple FairPlay, and Microsoft PlayReady
- KeyOS MultiKey includes a license release tool built to revoke playback licenses for songs a user has already downloaded
- 16 Jul
 Tool News & Updates 16 Jul
Tool News & Updates 16 JulSuno brings text-to-song to iMessage, letting iPhone users generate tracks inside Messages
- Suno added an iMessage extension on July 15, 2026, letting iPhone users generate a song from a text or voice prompt without leaving Messages.
- The update also brings male and female voice selection, sound-effect generation, and a new Mashup feature that combines any two songs.
- Suno generates about 7 million songs a day and is leaning into the TikTok trend of turning text messages into songs.
- 15 Jul
 Tool News & Updates 15 Jul
Tool News & Updates 15 JulBandLab Technologies buys Aiode, its AI studio trained on 100% licensed audio
- BandLab Technologies acquired Aiode on July 15, 2026, its third music-making platform alongside BandLab and Cakewalk
- Aiode says 100% of the audio behind its models is licensed and traceable to its source
- Its models are built with professional session musicians who direct how their own playing style is used
- 14 Jul
 Tool News & Updates 14 Jul
Tool News & Updates 14 JulLANDR puts $1 million into advances for artists who license their music to AI
- LANDR is adding a $1 million advance fund so Fair Trade AI artists can take money upfront instead of waiting on licensing revenue.
- The artist share of net licensing revenue rises from 20% to 25%, split by how much each artist contributed to the dataset.
- LANDR says the first Fair Trade AI payouts reach participating artists later this month, 2 years after the program launched in July 2024.
-
Free newsletter
Get this in your inbox — free
- AI Music Briefing — the week's biggest AI music news, the AI Music Lawsuit Tracker, and Music Intelligence.
- 1 tutorial every week — AI music promotion: from a 4-week song-release strategy to a music video in under 10 minutes.
- 10 Jul
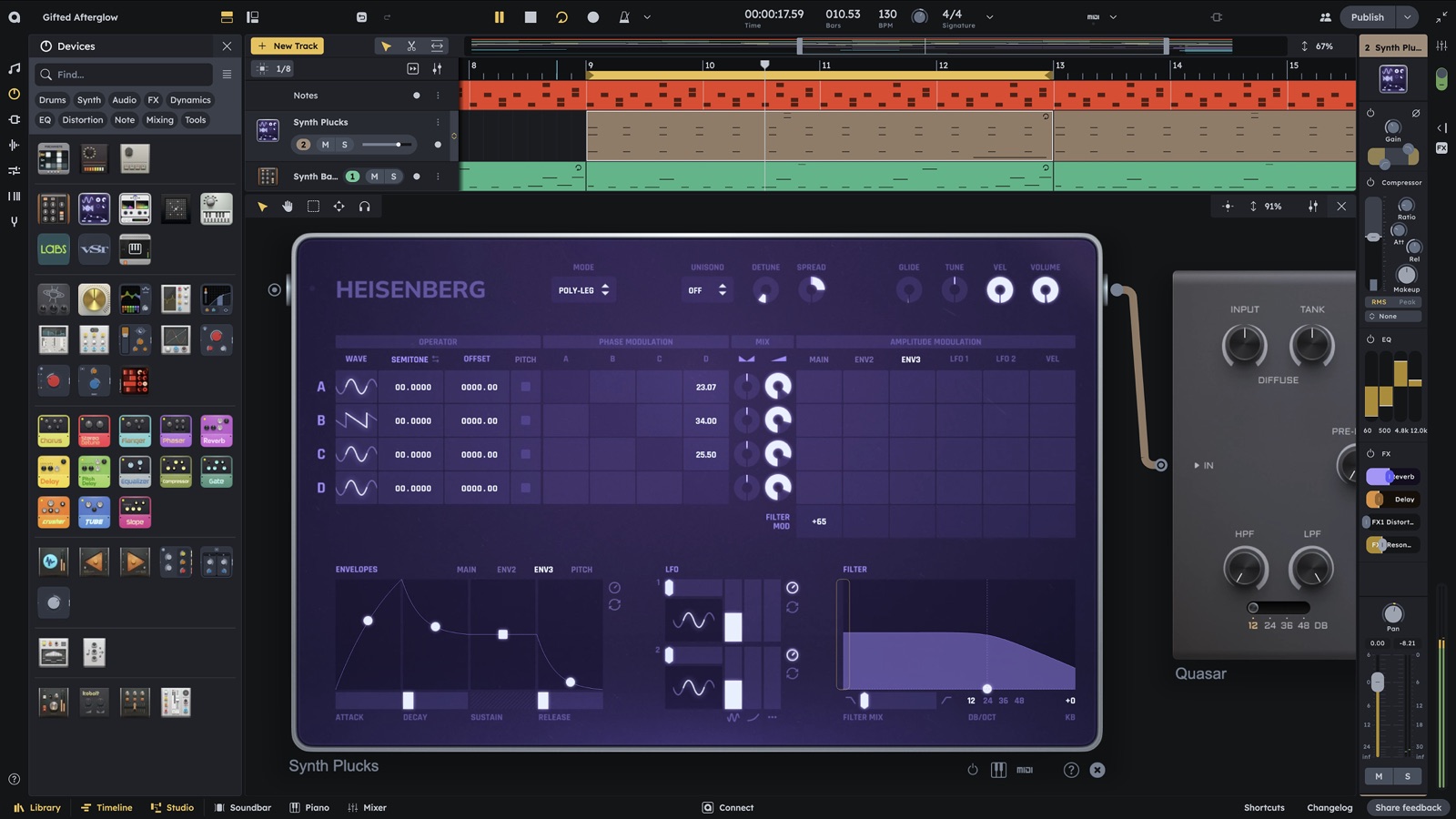 Tool News & Updates 10 Jul
Tool News & Updates 10 JulAudiotool 3.0 rebuilds its browser DAW for multiplayer, with an open-source AI SDK
- Audiotool 3.0 launched publicly on July 8, 2026, a ground-up rebuild of its free, browser-based DAW.
- It brings real-time multiplayer music creation to browsers and tablets, with native mobile versions coming soon.
- NEXUS, a new open-source SDK, lets anyone build instruments, effects, games, and AI-connected tools inside the platform.
- 10 Jul
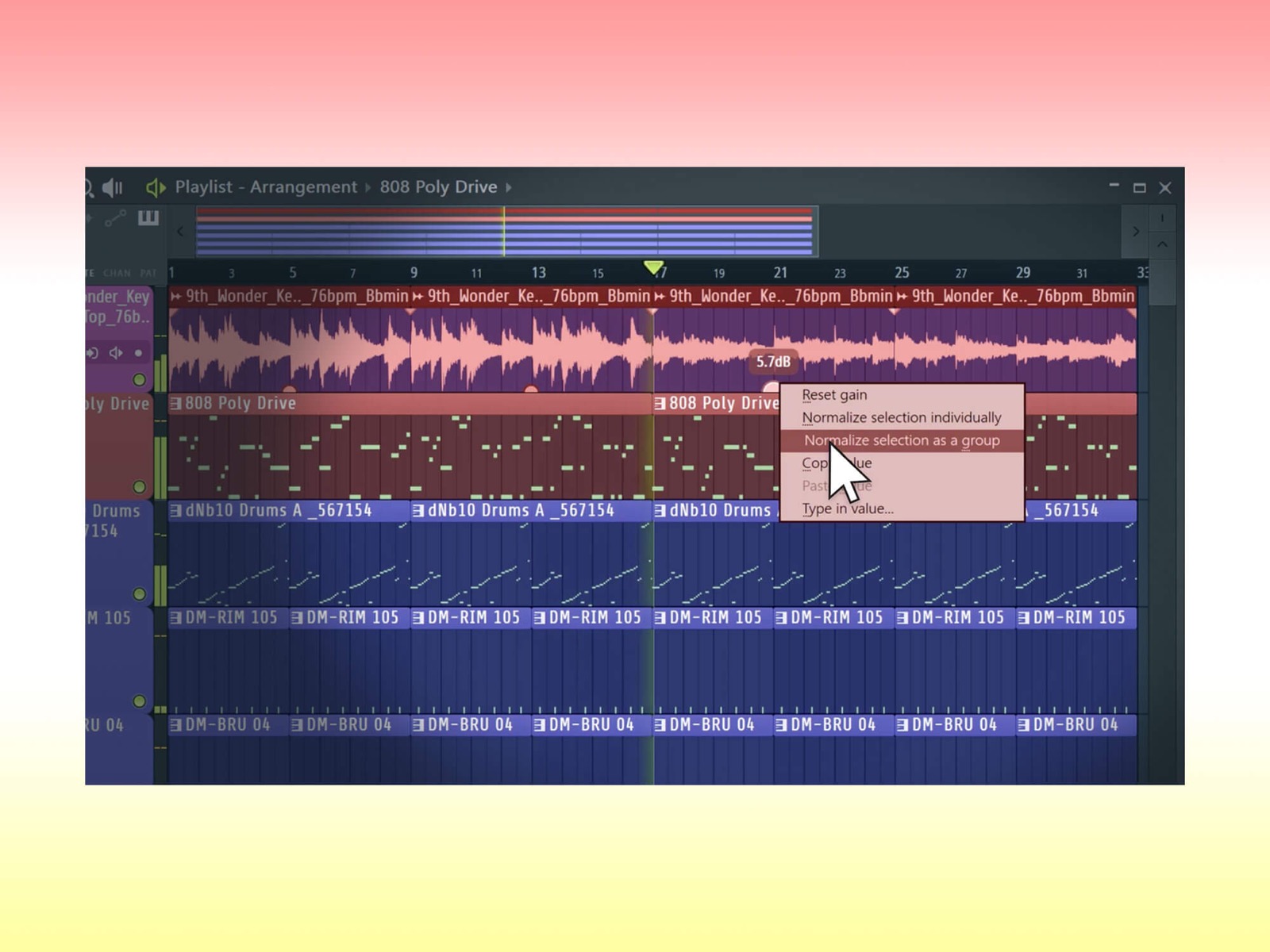 Tool News & Updates 10 Jul
Tool News & Updates 10 JulFL Studio 2026 lands with a smarter Gopher AI assistant and a no-AI-training pledge
- FL Studio 2026 launched on July 7, 2026, free for all existing license holders under Image-Line's Lifetime Free Updates policy.
- The Gopher AI assistant now takes multi-step instructions like routing mixer channels, setting levels, and generating Piano Roll content, and it does not train on user data.
- Image-Line says none of the projects stored in FL Cloud will be used to train AI.
- 10 Jul
 Tutorial 10 Jul
Tutorial 10 JulWhat's new in FL Studio 2026? A beginner's guide to every major update
- FL Studio 2026 landed on July 7, 2026 as a free update for every existing license holder.
- The rebuilt FLEX engine cuts CPU use by up to 50% and ships over 200 free presets across 8 new Core Series packs.
- The new Remix a Song tool detects a track's tempo and splits it into stems in 1 click from the Welcome window.
- 06 Jul
 Tool Roundup 06 Jul
Tool Roundup 06 Jul9 Best Generative Music Tools in 2026 (No AI Required)
- All 9 tools generate chords, melodies, basslines, and drum patterns from rules, probability, and music theory, with zero trained models involved.
- Reason 14 Players run inside any DAW through the Reason Rack Plugin (VST3, AU, AAX), from €159 paid once or €6.58 a month.
- Ableton Live 12 ships 5 MIDI Generators (Seed, Stacks, Rhythm, Shape, Euclidean) built on rules and randomization, not machine learning.
- 06 Jul
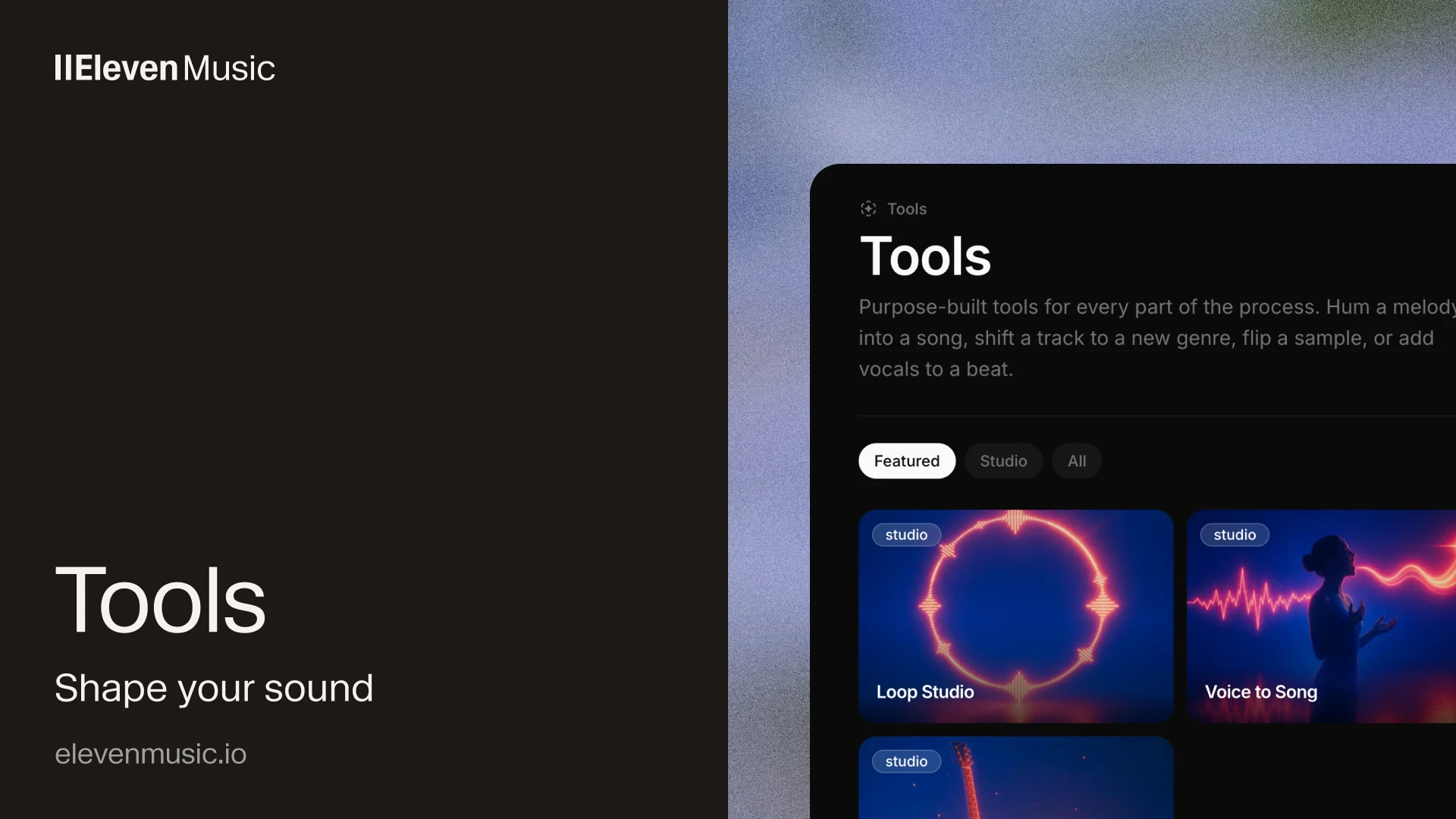 Tool News & Updates 06 Jul
Tool News & Updates 06 JulElevenMusic adds 4 Tools: Voice to Song, Loop Studio, Genreshift, and Unplugged
- ElevenLabs launched Tools on ElevenMusic on July 2, 2026, and all 4 are live in the app now.
- Voice to Song turns a rough phone-recorded vocal into a studio-quality track and keeps your melody and lyrics.
- Loop Studio generates a clean instrumental loop from a genre pick and a BPM.
- 06 Jul
 Tool News & Updates 06 Jul
Tool News & Updates 06 JuliZotope joins Boris FX, and your RX and Ozone licenses stay active
- Boris FX acquired iZotope on July 2, 2026, taking the maker of RX and Ozone out of the Native Instruments family.
- All iZotope licenses and subscriptions stay active, and support continues through the same channels and team.
- iZotope says it remains committed to selling both perpetual licenses and subscriptions under Boris FX.
- 03 Jul
 Tool News & Updates 03 Jul
Tool News & Updates 03 JulMadverse v2.0 lets independent artists keep 100% of their royalties
- Madverse relaunched as v2.0 on July 1, 2026, pitching one place for independent artists and labels to release, manage, promote, and monetise their music.
- Both subscription tiers now pay out 100% of royalties, up from 85% on Creator and 95% on Professional.
- The Creator plan costs Rs299 per month (Rs99 for the first month); the Professional plan is Rs3,999 per year.
- 03 Jul
 Tool News & Updates 03 Jul
Tool News & Updates 03 JulSuno explores a developer API to embed AI music generation in other apps
- Suno Chief Product Officer Jack Brody said on July 1, 2026 that the company is exploring a developer API, starting with a curated group of partners.
- Suno has no official public API today; developers have only built unofficial wrappers around its platform.
- The API would let outside apps send text prompts to Suno's models and receive finished audio, embedding generation into their own products.
- 01 Jul
 Tool News & Updates 01 Jul
Tool News & Updates 01 JulViberate launches an official MCP server, opening its music data to ChatGPT, Claude, and Gemini
- Viberate launched an official MCP server so any compatible AI assistant can query its data in plain language.
- The database covers 11 million artists, 100 million songs, 19 million playlists, 160,000 labels, and 7,000 festivals.
- A free tier gives basic access, and a paid plan adds more than 20 tools with a 20% founding discount for the first three months.
- 26 Jun
 Tool News & Updates 26 Jun
Tool News & Updates 26 JunOpenStage launches an MCP that connects your fan data to Claude, ChatGPT, and Gemini
- OpenStage launched OpenStage MCP, letting artists connect their fan data to Claude, ChatGPT, or Gemini and have the AI read, analyze, and act on it.
- The platform already powers fan data for more than 600 artists and 30 million fans, including Paul McCartney, Lana Del Rey, and Bad Bunny.
- In early testing, one manager's single prompt surfaced that an artist's fanbase had tripled in one city over six months.
Frequently asked questions
Where can I find the latest AI music tool launches and updates?
The AI music tool news category lists every launch, feature update, partnership, and pricing change, newest first. New stories go up most weekdays, and the Wednesday AI Musicpreneur newsletter rounds up the best tools and tutorials of the week.
Does The AI Musicpreneur test the AI music tools it covers?
Yes. Reviews, tutorials, and comparisons come from hands-on use on real music projects. Each tool page in the AI music tools directory lists pricing, pros, and cons from that testing. Launch coverage is marked as news; the review follows once I've used the tool.